Downsampled ImageNet datasets: ImageNet8x8, ImageNet16x16, ImageNet32x32 and ImageNet64x64
Github
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
Dataset
General information
We provide a set of downsampled versions of the original Imagenet dataset, as described by Chrabaszcz et al, “A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets”. Please cite it if you intend to use this dataset. In a nutshell, this includes all images of ImageNet, resized to 32 x 32 pixels by the ‘box’ algorithm from the Pillow library. ImageNet64, Imagenet16 and Imagenet8 are very similar, just resized to 64x64, 16x16 and 8x8 pixel, respectively.
Our downsampled datasets contain exactly the same number of images as the original ImageNet, i.e., 1281167 training images from 1000 classes and 50000 validation images with 50 images per class.
The datasets can be downloaded from http://image-net.org/download-images
The file format was inspired by the CIFAR dataset.
You need Python3 to unpickle files. Note that its default encoding differs from Python2.
# Note that this will work with Python3
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo)
return dict
There are 10 files with training data (“file train_data_batch_#”). Each of them contains a python dictionary with the following fields:
- ‘data’ - numpy array with uint8 numbers of shape samples x 3072. First 1024 numbers represent red channel, next 1024 numbers green channel, last 1024 numbers represent blue channel. See CIFAR website.
- ‘labels’- number representing image class, indexing starts at 1 and it uses mapping from the map_clsloc.txt file provided in original Imagenet devkit
- ‘mean’ - mean image computed over all training samples, included for convenience, usually first preprocessing step removes mean from all images.
One file with validation data (“val_data”) contains python dictionary with fields ‘data’ and ‘labels’ (There is no ‘mean’ field)
Usage in Python3
To read one of the files and use it in Lasagne framework (NCHW format) you would use:
def load_databatch(data_folder, idx, img_size=32):
data_file = os.path.join(data_folder, 'train_data_batch_')
d = unpickle(data_file + str(idx))
x = d['data']
y = d['labels']
mean_image = d['mean']
x = x/np.float32(255)
mean_image = mean_image/np.float32(255)
# Labels are indexed from 1, shift it so that indexes start at 0
y = [i-1 for i in y]
data_size = x.shape[0]
x -= mean_image
img_size2 = img_size * img_size
x = np.dstack((x[:, :img_size2], x[:, img_size2:2*img_size2], x[:, 2*img_size2:]))
x = x.reshape((x.shape[0], img_size, img_size, 3)).transpose(0, 3, 1, 2)
# create mirrored images
X_train = x[0:data_size, :, :, :]
Y_train = y[0:data_size]
X_train_flip = X_train[:, :, :, ::-1]
Y_train_flip = Y_train
X_train = np.concatenate((X_train, X_train_flip), axis=0)
Y_train = np.concatenate((Y_train, Y_train_flip), axis=0)
return dict(
X_train=lasagne.utils.floatX(X_train),
Y_train=Y_train.astype('int32'),
mean=mean_image)
How to regenerate the datasets (Optional)
-
Download the original ImageNet dataset.
-
Use image_resizer_imagenet.py script to resize images. See –help for more info.
python image_resizer_imagent.py -i ~/images/ILSVRC2015/Data/CLS-LOC/train -o ~/data/ -s 32 -a box -r -j 10
python image_resizer_imagent.py -i ~/images/ILSVRC2015/Data/CLS-LOC/val -o ~/data/val -s 32 -a box
Please consider checking the log files generated after the scripts are finished. Some images might cause issues. Consider to manually copy the content of problematic images and resave them to fix the issue.
- Use image2numpy_imagenet_train.py and image2numpy_imagenet_val.py script to create files with training images and files with validation images.
python image2numpy_imagenet_train.py -i ~/data/box -o ~/out_data_train
python image2numpy_imagenet_val.py -i ~/data/val/box -o ~/out_data_val
Note that the first script requires a lot of RAM, it should not be hard however to change the code to use less memory. Training images are first randomly shuffled, then divided into 10 groups and saved in 10 files.
Displaying images
Use script test.py to generate a set of large images containing all images from a given file. Additionally it is possible to display histograms showing how many images are in this file for each of the classes.




Validation images from Imagenet64, Imagenet32, Imagenet16, Imagenet8.
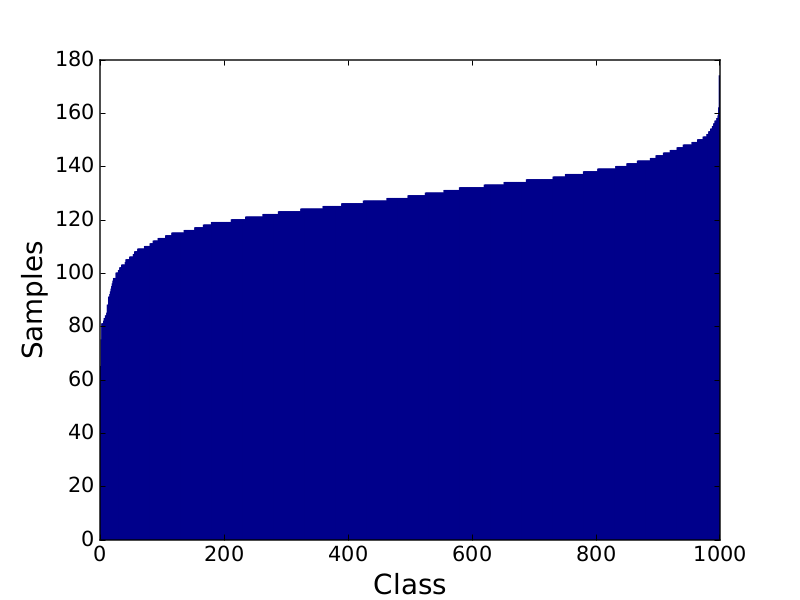 Distribution of classes for one of the training files. (Sorted for better visualization)
Distribution of classes for one of the training files. (Sorted for better visualization)
Validation performance
The table below shows the best validation error rates obtained on the downsampled ImageNet datasets:
| Dataset | Network | Top 1 Error | Top 5 Error | Date |
|---|---|---|---|---|
| Imagenet 16 | WRN-20-10 | 59.94% | 35,10% | 27.06.17 : |
| Imagenet 32 | WRN-28-10 | 40,96% | 18,87% | 04.05.17 : |
| Imagenet 64 | WRN-36-5 | 32,34% | 12,64% | 27.06.17 : |